Statistical Patterns and Random Phenomena - AP Statistics
Card 1 of 560
Let us suppose we have population data where the data are distributed Poisson
(see the figure for an example of a Poisson random variable). 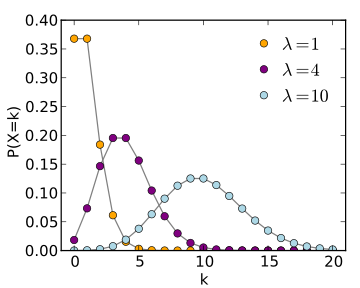
Which distribution increasingly approximates the sample mean as the sample size increases to infinity?
Let us suppose we have population data where the data are distributed Poisson
(see the figure for an example of a Poisson random variable).
Which distribution increasingly approximates the sample mean as the sample size increases to infinity?
Tap to reveal answer
The Central Limit Theorem holds that for any distribution with finite mean and variance the sample mean will converge in distribution to the normal as sample size 
 .
.
The Central Limit Theorem holds that for any distribution with finite mean and variance the sample mean will converge in distribution to the normal as sample size
← Didn't Know|Knew It →
Which of the following is NOT a discrete random variable?
Which of the following is NOT a discrete random variable?
Tap to reveal answer
By definition, a discrete random variable is a random variable whose values can be "counted" one by one. A continuous random variable is a random variable that can take any value on a certain interval. Of these choices, the number of lip products, the amount of money, and the number of midterms taken are all discrete random variables, as the respective values can be counted; however, the time taken to watch the first four seasons of a TV show is a continuous random variable, as not everyone will take the same amount of time to watch all those episodes (i.e. some might fastf-orward/replay parts of episodes).
By definition, a discrete random variable is a random variable whose values can be "counted" one by one. A continuous random variable is a random variable that can take any value on a certain interval. Of these choices, the number of lip products, the amount of money, and the number of midterms taken are all discrete random variables, as the respective values can be counted; however, the time taken to watch the first four seasons of a TV show is a continuous random variable, as not everyone will take the same amount of time to watch all those episodes (i.e. some might fastf-orward/replay parts of episodes).
← Didn't Know|Knew It →
Which of the following is a sampling distribution?
Which of the following is a sampling distribution?
Tap to reveal answer
The correct answer is the distribution of average height statistics that could happen from all possible samples of college students. Remember that a sampling distribution isn't just a statistic you get form taking a sample, and isn't just a piece of data you get from doing sampling. Instead, a sampling distribution is a distribution of sample statistics you could get from all of the possible samples you might take from a given population.
The correct answer is the distribution of average height statistics that could happen from all possible samples of college students. Remember that a sampling distribution isn't just a statistic you get form taking a sample, and isn't just a piece of data you get from doing sampling. Instead, a sampling distribution is a distribution of sample statistics you could get from all of the possible samples you might take from a given population.
← Didn't Know|Knew It →
A survey company samples 60 randomly selected college students to see if they own an American Express credit card. One percent of all college students own an American Express credit card. Does the Central Limit Theorem apply?
A survey company samples 60 randomly selected college students to see if they own an American Express credit card. One percent of all college students own an American Express credit card. Does the Central Limit Theorem apply?
Tap to reveal answer
No. Whenever we get a "proportion" question we need to check whether  and whether
and whether \geq10") .
.
In this problem,  .
.
Therefore,
 .
.
So the central limit theorem does not apply.
No. Whenever we get a "proportion" question we need to check whether
In this problem,
Therefore,
So the central limit theorem does not apply.
← Didn't Know|Knew It →
Which of the following populations has a precisely normal distribution?
Which of the following populations has a precisely normal distribution?
Tap to reveal answer
A normal distribution is one in which the values are evenly distributed both above and below the mean. A population has a precisely normal distribution if the mean, mode, and median are all equal. For the population of 3,4,5,5,5,6,7, the mean, mode, and median are all 5.
A normal distribution is one in which the values are evenly distributed both above and below the mean. A population has a precisely normal distribution if the mean, mode, and median are all equal. For the population of 3,4,5,5,5,6,7, the mean, mode, and median are all 5.
← Didn't Know|Knew It →
If a population has a normal distribution, the number of values within one positive standard deviation of the mean will be . . .
If a population has a normal distribution, the number of values within one positive standard deviation of the mean will be . . .
Tap to reveal answer
In a normal distribution, the number of values within one positive standard deviation of the mean is equal to the number of values within one negative standard deviation of the mean. The reason for this is that the values below the population mean exactly parallel the values above the mean.
In a normal distribution, the number of values within one positive standard deviation of the mean is equal to the number of values within one negative standard deviation of the mean. The reason for this is that the values below the population mean exactly parallel the values above the mean.
← Didn't Know|Knew It →
Which is the following is true about the standard normal distribution?
Which is the following is true about the standard normal distribution?
Tap to reveal answer
The standard normal distribution is just like any other normal distribution that you might have looked at except that it has a standard deviation of 1 and a mean of 0.
The standard normal distribution is just like any other normal distribution that you might have looked at except that it has a standard deviation of 1 and a mean of 0.
← Didn't Know|Knew It →
Cheyenne is worried about food thieves in the break room at work, and she believes that, as the week progresses, and people get lazy and ready for the weekend, more food theft occurs. She gathered the following data on number of thefts per day, and fell very behind in her work for a week.
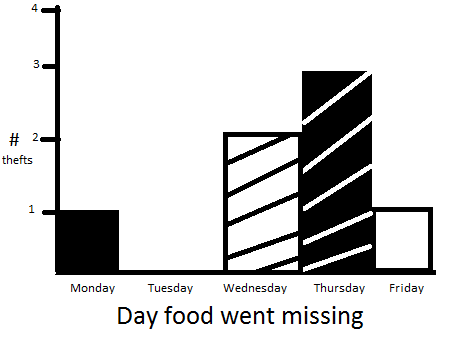
Which of the following statements about the data are true?
i: the data is normally distributed
ii: the data is skewed left
iii: the data supports Cheyenne's theory
iv: the data is a representative sample
Cheyenne is worried about food thieves in the break room at work, and she believes that, as the week progresses, and people get lazy and ready for the weekend, more food theft occurs. She gathered the following data on number of thefts per day, and fell very behind in her work for a week.
Which of the following statements about the data are true?
i: the data is normally distributed
ii: the data is skewed left
iii: the data supports Cheyenne's theory
iv: the data is a representative sample
Tap to reveal answer
The data is not normal by virtue of being skewed left, which also supports Cheyenne's theory... there is no way of knowing wether this data was a representative sample, but also no option with ii, iii and iv was provided to avoid frustration/confusion
The data is not normal by virtue of being skewed left, which also supports Cheyenne's theory... there is no way of knowing wether this data was a representative sample, but also no option with ii, iii and iv was provided to avoid frustration/confusion
← Didn't Know|Knew It →
Alex took a test in physics and scored a 35. The class average was 27 and the standard deviation was 5.
Noah took a chemistry test and scored an 82. The class average was 70 and the standard deviation was 8.
Show that Alex had the better performance by calculating -
-
Alex's standard normal percentile and
-
Noah's standard normal percentile
Alex took a test in physics and scored a 35. The class average was 27 and the standard deviation was 5.
Noah took a chemistry test and scored an 82. The class average was 70 and the standard deviation was 8.
Show that Alex had the better performance by calculating -
-
Alex's standard normal percentile and
-
Noah's standard normal percentile
Tap to reveal answer
Alex -
/5 = 1.6 = .945") on the z-table
on the z-table
Noah -
/8=1.5=.933") on the z-table
on the z-table
Alex -
Noah -
← Didn't Know|Knew It →
Find the area under the standard normal curve between Z=1.5 and Z=2.4.
Find the area under the standard normal curve between Z=1.5 and Z=2.4.
Tap to reveal answer



← Didn't Know|Knew It →
Given a fair coin, what is the probability of obtaining 5 heads and 3 tails from 8 tosses?
Given a fair coin, what is the probability of obtaining 5 heads and 3 tails from 8 tosses?
Tap to reveal answer
First, there are 8 trials and either choose 5 or 3 for heads or tails, respectively. Using this knowledge:  . Next, the chance for either heads or tails is 0.5 and there are 5 heads and 3 tails. Thus:
. Next, the chance for either heads or tails is 0.5 and there are 5 heads and 3 tails. Thus: ^5(0.5)^3 or (0.5)^8") . Multiply:
. Multiply:  and
and ^8") and obtain 0.2188.
and obtain 0.2188.
First, there are 8 trials and either choose 5 or 3 for heads or tails, respectively. Using this knowledge:
← Didn't Know|Knew It →
There are 52 total cards in a full deck of playing cards. If a card dealer chooses 4 cards from the deck at random and without replacement, what is the chance that the dealer draws four kings as the first four cards?
There are 52 total cards in a full deck of playing cards. If a card dealer chooses 4 cards from the deck at random and without replacement, what is the chance that the dealer draws four kings as the first four cards?
Tap to reveal answer
In a normal deck of playing cards, there are 4 kings. Thus, when the dealer draws the first card, the chance of the dealer obtaining a king is 4 out of 52. Because this card has been picked and is not replaced, the chance that the next card chosen is a king is 3 out of 52. The chance the third card is a king is 2 out of 52 and the fourth card is 1 out of 52. Each of these events is multiplied together, thus obtaining the correct answer, 0.0000037.
In a normal deck of playing cards, there are 4 kings. Thus, when the dealer draws the first card, the chance of the dealer obtaining a king is 4 out of 52. Because this card has been picked and is not replaced, the chance that the next card chosen is a king is 3 out of 52. The chance the third card is a king is 2 out of 52 and the fourth card is 1 out of 52. Each of these events is multiplied together, thus obtaining the correct answer, 0.0000037.
← Didn't Know|Knew It →
A fair coin is flipped three times and comes up heads each time. What is the probability that the fourth toss will also come up heads?
A fair coin is flipped three times and comes up heads each time. What is the probability that the fourth toss will also come up heads?
Tap to reveal answer
Remember, no matter what the previous trials' results, the probability of a head (or tail) does not change from  because each trial is independent of the others.
because each trial is independent of the others.
Remember, no matter what the previous trials' results, the probability of a head (or tail) does not change from
← Didn't Know|Knew It →
Which parameters define the normal distribution?
Which parameters define the normal distribution?
Tap to reveal answer
The two main parameters of the normal distribution are  and
and  .
.  is a location parameter which determines the location of the peak of the normal distribution on the real number line.
is a location parameter which determines the location of the peak of the normal distribution on the real number line.  is a scale parameter which determines the concentration of the density around the mean. Larger
is a scale parameter which determines the concentration of the density around the mean. Larger  's lead the normal to spread out more than smaller
's lead the normal to spread out more than smaller  's.
's.
The two main parameters of the normal distribution are
← Didn't Know|Knew It →
In order to be considered a normal distribution, a data set (when graphed) must follow a bell-shaped symmetrical curve centered around the mean.
It must also adhere to the empirical rule that indicates the percentage of the data set that falls within (plus or minus) 1, 2 and 3 standard deviations of the mean.
In order to be a normal distribution, what percentage of the data set must fall within:
-

-

-

In order to be considered a normal distribution, a data set (when graphed) must follow a bell-shaped symmetrical curve centered around the mean.
It must also adhere to the empirical rule that indicates the percentage of the data set that falls within (plus or minus) 1, 2 and 3 standard deviations of the mean.
In order to be a normal distribution, what percentage of the data set must fall within:
Tap to reveal answer
- Percentile for Z=1 is .8413 - or - .1587 in one tail - or - .3174 in both tails -
1 - .3174=.6826
- Percentile for Z=2 is .9772 - or - .0228 in one tail - or - .0456 in both tails -
1 - .0456=.9544
- Percentile for Z=3 is .9987 - or - .0013 in one tail - or - .0026 in both tails -
1 - .0026=.9974
- Percentile for Z=1 is .8413 - or - .1587 in one tail - or - .3174 in both tails -
1 - .3174=.6826
- Percentile for Z=2 is .9772 - or - .0228 in one tail - or - .0456 in both tails -
1 - .0456=.9544
- Percentile for Z=3 is .9987 - or - .0013 in one tail - or - .0026 in both tails -
1 - .0026=.9974
← Didn't Know|Knew It →
All normal distributions can be described by two parameters: the mean and the variance. Which parameter determines the location of the distribution on the real number line?
All normal distributions can be described by two parameters: the mean and the variance. Which parameter determines the location of the distribution on the real number line?
Tap to reveal answer
The mean determines where the normal distribution lies on the real number line, while the variance determines the spread of the distribution.
The mean determines where the normal distribution lies on the real number line, while the variance determines the spread of the distribution.
← Didn't Know|Knew It →
Consider a normal distribution with a mean of  and a standard deviation of
and a standard deviation of  . Which of the following statements are true according to the Empirical Rule?
. Which of the following statements are true according to the Empirical Rule?
 of observations are at least
of observations are at least  .
. of observations are between
of observations are between  and
and  .
. of observations are between
of observations are between  and
and  .
.
Consider a normal distribution with a mean of
Tap to reveal answer
-
and 3) are true by definition of the Empirical Rule - also known as the 68-95-99.7 Rule. Using our information with mean of 100 and a standard deviation of 5 we can create a bell curve with 100 in the middle. One standard deviation out from the mean would give us a range from 95 to 105 and would be in our 68% section. If we go two standard deviations out from 100 we would get the range 90 to 110 thus lying in the 95% section. Lastly, when we go out 3 standard deviations we get a range of 85 to 115 thus falling within the 99.7% section.
-
can be deduced as true because it means that 68% of observations are between 95 and 105, and removing one of those bounds (namely, the upper one) adds the 16%, since  , of observations larger than 105 leading to 68 + 16 = 84% of observations greater than 95.
, of observations larger than 105 leading to 68 + 16 = 84% of observations greater than 95.
-
and 3) are true by definition of the Empirical Rule - also known as the 68-95-99.7 Rule. Using our information with mean of 100 and a standard deviation of 5 we can create a bell curve with 100 in the middle. One standard deviation out from the mean would give us a range from 95 to 105 and would be in our 68% section. If we go two standard deviations out from 100 we would get the range 90 to 110 thus lying in the 95% section. Lastly, when we go out 3 standard deviations we get a range of 85 to 115 thus falling within the 99.7% section.
-
can be deduced as true because it means that 68% of observations are between 95 and 105, and removing one of those bounds (namely, the upper one) adds the 16%, since
← Didn't Know|Knew It →
What is the relationship between the mean and the median in a normally distributed population?
What is the relationship between the mean and the median in a normally distributed population?
Tap to reveal answer
A normal distrubtion is completely symmetrical and has not outliers. This means that the mean is not pulled to either side by outliers and should lie directly in the middle along with the median (the middle number of the distribution).
A normal distrubtion is completely symmetrical and has not outliers. This means that the mean is not pulled to either side by outliers and should lie directly in the middle along with the median (the middle number of the distribution).
← Didn't Know|Knew It →
Which is the following is NOT a property of the normal distribution?
Which is the following is NOT a property of the normal distribution?
Tap to reveal answer
The empirical rule tells us that the probability that a random data point is within one standard deviation of the mean is approximately 68%, not 78%.
The empirical rule tells us that the probability that a random data point is within one standard deviation of the mean is approximately 68%, not 78%.
← Didn't Know|Knew It →
When

and

Find
") .
.
When
and
Find
Tap to reveal answer
\div6=-1.17")

\div6=1")

=.8413 - .121 = .7203")
← Didn't Know|Knew It →